Demand for data scientists is booming and will only increase
Fueled by big data and AI, demand for data science skills is growing exponentially, according to job sites. The supply of skilled applicants, however, is growing at a slower pace.
It's a great time to be a data scientist entering the job market. That's according to recent data from job sites Indeed and Dice.
"The job of a data scientist has only grown sexier," said Andrew Flowers, an economist at Indeed, based in Austin, Texas, and author of the Indeed report. "More employers than ever are looking to hire data scientists."
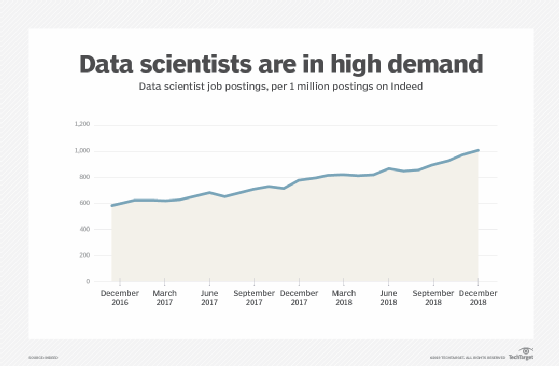
The January report from Indeed, one of the top job sites, showed a 29% increase in demand for data scientists year over year and a 344% increase since 2013 -- a dramatic upswing. But while demand -- in the form of job postings -- continues to rise sharply, searches by job seekers skilled in data science grew at a slower pace (14%), suggesting a gap between supply and demand.
Similarly, data from technology job site Dice showed the number of data science job postings on its platform -- as a proportion of total posted jobs -- has increased about 32% year over year, and the site considers data science a "high-demand skill." Dice noted that the job postings are from companies in a wide variety of industries, not just tech.
Forrester Research analyst Brandon Purcell said demand for data scientists will only grow, as organizations increasingly rely on data-driven insights.
"To acquire and retain today's increasingly empowered customers, companies need to harness the insights in their data to personalize experiences at scale," Purcell said. "Data scientists are crucial in turning the massive amount of data companies capture into action. They've always been in high demand, but until recently, only large enterprises and digital natives were willing to make the significant investment. Now, almost everyone is."
The rise of AI and machine learning may also be a factor in the dramatic increase in demand for data scientists, Purcell said.
"Honestly, a lot of this is because of branding," Purcell said. "Many companies see data scientists as the key to embracing AI or machine learning, which are the hottest technologies out there."
Unfortunately, the reality is data scientists are only a small part of an organization's AI strategy, Purcell said. Data engineers who understand where data resides and what it contains are also necessary, as are DevOps professionals who can operationalize a machine learning model at scale.
The number of job postings for the related and much-talked-about skill of deep learning has more than doubled year over year, according to Dice.
Desirable, but hard-to-find data scientists sought
In his Indeed report, Flowers cited recruiting agency Burtch Works and data science competitions platform Kaggle, saying data scientists typically are expected to have some fluency in at least one programming language -- Python and R being the favorites. Data scientists also are expected to have experience in tools like Hive, BigQuery, AWS, Spark and Hadoop, as well as training in statistical modeling, machine learning and programming.
Along with statistical and machine learning modeling using Python or R, Feyzi Bagirov, data science adviser at San Francisco-based B2B data insight vendor Metadata.io, said he's also seeing more demand for skills in SQL, NoSQL databases, Apache Spark and relational database management systems (RDBMS). SQL is a standard skill for most of the data analytics and data science openings, and most corporate data still sits on RDBMS legacy systems, Bagirov added.
Purcell said organizations err when they tend to look for the "unicorn data scientist" that combines the skills of data engineer, machine learning expert and business executive.
"That's the wrong approach, because those people don't exist," Purcell said. "Look for the machine learning expert who can use R, Python or SAS and understand which algorithms to apply to different situations. Then, team the person with the other two personas, which you already have in-house."
The Indeed report noted that many data scientists' formal education is in disciplines like computer science, statistics or a quantitative social science. Of the recent data scientist candidate profiles present on Dice, 27% have a master's degree, 10% have a doctorate and 13% have a bachelor's degree.
The growth in data scientist job postings on Indeed, from December 2016 to December 2018.
Supply-demand gap
In August 2018, LinkedIn reported that there's a shortage of 151,717 people with data science skills in the U.S., based on data from its platform. Combine that with a 15% discrepancy between job postings and job searches on Indeed, it's evident that demand for data scientists outstrips supply.
According to the Indeed report, data science job searches follow a somewhat seasonal pattern. In 2017 and 2018, searches peaked in April or March, which might reflect the influx of students searching for internships or soon-to-be graduates looking for first their jobs, Flowers said.
"After all, the job data scientist has been hyped for at least six years now, and college students majoring in computer science are on the rise," Flowers said. "But, as the growth in postings for data scientists shows, even with that boom, there potentially may not be enough skilled applicants."
Data scientists are crucial in turning the massive amount of data companies capture into action.
Brandon Purcellanalyst, Forrester Research
Purcell said he thinks the supply-demand gap for data scientists will definitely narrow, as there are more data scientists entering the job market -- either from graduate programs or after getting "nanodegrees" from massive open online courses.
After doing his own calculations (in true data scientist fashion -- see sidebar), Bagirov said he thinks the supply-demand gap won't close anytime soon. Academia still struggles to propagate data science, he added.
"Universities are having a hard time finding quality faculty to facilitate their programs' growth, as the salaries in the industry for data scientists are much higher than those in academia," Bagirov said.
Feyzi Bagirov, data science adviser at Metadata.io, did some simple math to determine if the gap between the supply and demand for data scientists will close in the foreseeable future.
Editor's note: Bagirov's remarks have been edited for clarity and length.
Feyzi Bagirov: In 2016, Huffington Post indicated there are approximately 1.5 [million] to 3 million data scientists in the world. Extrapolating from the [estimated supply-demand gap reported on Indeed], the need last year would have been between around 1.69 [million] and 3.19 million data scientists.
Assuming there are around 200 graduate programs [graduating students within one to one and a half years] with each graduating 500 to 1,000 students per year, that adds to the workforce around 100,000 to 200,000 new data analytics and data science graduates. With little work experience, they will need at least one to two years to gain the experience.
If you add another 500,000 students coming from the adjacent majors -- computer science, statistics -- and data science boot camps, which vary dramatically in their quality and outcomes, the number would still not be enough to fill the need, and it is not going to close anytime soon.
Paying for data science practitioners
It's no surprise, given the high demand for data scientists, that salaries for the position are also elevated. According to an annual Dice Salary Survey, the role of data scientist carries an average salary of $106,000 a year.
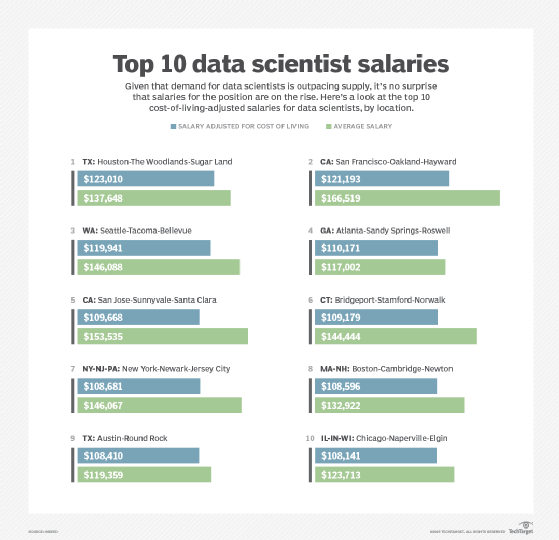
Indeed data showed the top cities for data scientists are Houston and San Francisco, with average cost-of-living-adjusted salaries of just over $120,000. By comparison, the nationwide average in 2017 for computer programmers was $88,000 and $107,000 for software developers, according to the Bureau of Labor Statistics.