big data management
What is big data management?
Big data management is the organization, administration and governance of large volumes of both structured and unstructured data. The goal of big data management is to ensure a high level of data quality and accessibility for business intelligence and big data analytics applications.
Companies, government agencies and other organizations use big data management strategies to deal with fast-growing data pools, typically involving many terabytes or even petabytes stored in various file formats. Effective big data management helps locate valuable information in large sets of unstructured and semistructured data from various sources, including call records, system logs, internet of things and other sensors, images, and social media sites.
Most big data environments go beyond relational databases and traditional data warehouse platforms to incorporate technologies that are suited to data processing and storing nontransactional forms of data. The increasing focus on collecting and analyzing big data is shaping new data platforms and architectures that often combine data warehouses with big data systems.
As part of the big data management process, companies must decide what data must be kept for business or compliance reasons, what data can be disposed of, and what data should be analyzed to improve business processes or provide a competitive advantage. This process requires careful data classification so that, ultimately, smaller sets of data can be analyzed quickly and productively.
Top challenges in managing big data
Big data is usually complex. In addition to its volume and variety, it often includes streaming data and other types of data that are created and updated at a high velocity. As a result, processing and managing big data are complicated tasks. For data management teams, the biggest challenges faced with big data deployments include the following:
- Dealing with large amounts of data. Big data sets don't need to be massive, but they commonly are. Also, data is frequently spread across different processing platforms and data storage repositories. The scale of data volumes that are typically involved makes it difficult to manage them effectively.
- Fixing data quality problems. Big data environments often include raw data that hasn't been cleansed, including data from different source systems that might not be entered or formatted consistently. That makes data quality management a challenge for teams, which need to identify and fix data errors, variances, duplicate entries and other issues in data sets.
- Integrating different data sets. Similar to the challenge of managing data quality, the data integration process with big data is complicated by the need to pull together data from various sources for analysis. In addition, traditional extract, transform and load (ETL) integration approaches often aren't suited to big data because of its variety and processing velocity.
- Preparing data for analytics applications. Data preparation for advanced analytics can be a lengthy process, and big data makes it even more challenging. Raw data sets often must be consolidated, filtered, organized and validated on the fly for individual applications. The distributed nature of big data systems also complicates efforts to gather the required data.
- Ensuring big data systems can scale as needed. Big data workloads require a lot of processing and storage resources. That can strain the performance of big data systems if they aren't designed to deliver the required processing capacity. It's a balancing act, though. Deploying systems with excess capacity adds unnecessary costs for businesses.
- Governing large data sets. Without sufficient data governance oversight, data from different sources might not be harmonized, and sensitive data might be collected and used improperly. But governing big data environments creates new challenges because of the unstructured and semistructured data they contain, plus the frequent inclusion of external data sources.

Benefits of big data management
When done correctly, big data management can yield long-term benefits, including the following:
- Cost savings. Proper big data management helps organizations reduce expenses with increased efficiency through improvements such as optimized resource allocation and reduced latency and downtime.
- Improved accuracy. Implementing a framework for handling massive data volumes ensures the data is well formed, cleansed and error-free. Organized and reliable data leads to more accurate data analytics results.
- Personalized marketing. When quality data is used to gain insights about consumers, organizations can provide more personalized marketing strategies and customer service.
- Competitive advantages. With quality data and correct management practices, organizations can have advanced analytics capabilities that give them an advantage over their competitors that don't have the same standards for big data management.
Best practices for big data management
Big data management sets the stage for successful analytics initiatives that drive better business decision-making and strategic planning. What follows is a list of best practices to adopt in big data programs to put them on the right track:
- Develop a detailed strategy and roadmap upfront. Organizations should start by creating a strategic big data plan that defines business goals, assesses data requirements, and maps out data applications and system deployments. The strategy should include a review of data management processes and skills to identify any gaps that need to be filled.
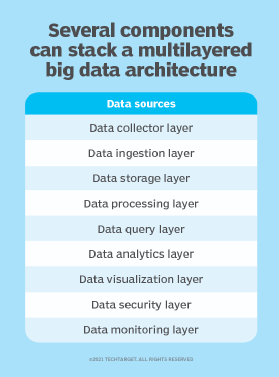
- Design and implement a solid architecture. A well-designed big data architecture includes various layers of systems and tools that support data management activities, ranging from ingestion, processing and storage to data quality, integration and preparation work.
- Stay focused on business goals and needs. Data management teams must work closely with data scientists, data analysts and business users to make sure big data environments meet an organization's needs for information to enable more data-driven decisions.
- Eliminate disconnected data silos. To avoid data integration problems and ensure relevant data is accessible for analysis, a big data architecture should be designed without siloed systems. It also offers the opportunity to connect existing data silos as source systems so that they can be combined with other data sets.
- Be flexible on managing data. Data scientists commonly need to customize how they manipulate data for machine learning, predictive analytics and other types of big data analytics applications. In some cases, they analyze full sets of raw data, enabling an iterative approach to data management.
- Put strong access and governance controls in place. While governing big data is a challenge, it's a must, along with user access controls and data security protections. Security measures help organizations comply with data privacy laws regulating the collection and use of personal data. Well-governed data also leads to high-quality and accurate analytics results.
Big data management tools and capabilities
There's a variety of platforms and tools for managing big data, with both open source and commercial versions available for many of them. The list of big data technologies and analytics tools that can be deployed, often in combination with one another, includes distributed processing frameworks Apache Hadoop and Apache Spark, stream processing engines, cloud object storage services, cluster management software, Structured Query Language (SQL) query engines, data lake and data warehouse platforms, and NoSQL databases.
To enable easier scalability and more flexibility, big data workloads are often run in the cloud, where businesses can set up their own systems or use managed services offerings. Big data management vendors include the leading cloud platform providers: AWS, Google and Microsoft.
Mainstream data management tools are key components for managing big data. They include data integration software supporting multiple integration techniques, such as the following:
- Traditional ETL processes.
- An alternative approach called extract, load and transform that loads data as is into big data systems so that it can be transformed later as needed.
- Real-time integration methods such as change data capture.
Data quality tools that automate data profiling, cleansing and validation are commonly used in the field of big data science too.
The future of big data management
Among the various approaches and tools that will help organizations deal with big data challenges in the future are the following:
- Artificial intelligence (AI) and machine learning. AI and machine learning tools are starting to be used to analyze big data sets to glean insights, patterns and trends.
- Cloud storage. As organizations use larger volumes of data, cloud computing platforms will continue to provide the storage space needed to house them.
- Improved analytics. The need for real-time analytics and data analysis will increase as organizations are required to make decisions based on up-to-date information.
- Data governance and security. Both governance and security will continue to be an important part of big data management to ensure compliance with local, state and federal laws, as well as the privacy of personal data.
- DataOps. To deal with big data, more organizations are adopting DataOps practices to streamline data management. This eliminates data silos and emphasizes collaboration among developers, data scientists, analysts and other stakeholders.
- Democratization. Democratizing data management can make everyday data owners stewards of their own data without needing the associated technical skills. For example, a data fabric lets users access data through a single view even when it's stored in various platforms.
Big data management is crucial for organizations that deal with vast data volumes, but big data must be culled from various sources first. Discover how the big data collection process works, along with techniques and challenges organizations need to know to be successful at it.





