What is business process management? A guide to BPM

Business process management (BPM) is a structured approach to improving the processes organizations use to get work done, serve their customers and generate business value. A business process is an activity or set of activities that helps accomplish an organization's goals, such as increasing profits or promoting workforce diversity. BPM uses various methods to improve a business process by analyzing it, modeling how it works in different scenarios, implementing changes, monitoring the new process and continuously improving its ability to drive desired business outcomes and results.
BPM is a broad discipline and, by definition, a dynamic one given how the organizational roles, rules, tactics, business goals and other elements it encompasses are constantly changing. Over the years, BPM has accommodated a variety of optimization methodologies, from Six Sigma and lean management to Agile.
As business processes at some companies became too large and complex to be managed without the aid of automated tools, BPM software products were developed to support large-scale business change. These enabling BPM technologies have in turn evolved, driven by advances in AI, machine learning and other so-called intelligent technologies that are providing new ways to discover, design, measure, improve and automate workflows. With the rise of digital business, BPM's traditional focus on back-end processes has shifted to now include the optimization of customer and employee systems of engagement.
Guide to BPM
As a discipline, BPM can also be confusing. Its practice varies widely among organizations depending on their size, process maturity, technical sophistication, corporate culture and resources. It can be narrow or large in scope: BPM's principles and techniques can be applied to the management of a single process, such as bringing on a new customer, or to a major business transformation requiring the implementation of radically new processes. The success of a BPM initiative depends to a great degree on an organization's capacity to see value in process improvement.
To help companies large and small get more out of their business processes, this comprehensive guide to BPM explains what it is, its benefits, the challenges it poses and best practices for using it effectively. You'll also find examples of business process automation and process improvement projects, an overview of the latest BPM tools and insight on what the future of BPM might look like.
Throughout the guide, there are hyperlinks to related articles that cover these topics in more depth, so be sure to click on them for additional expert advice. The links also connect readers to detailed definitions of important concepts in BPM, such as business process mapping, Business Process Model and Notation (BPMN) and workflow management.
Why is business process management important?
Business process management is important because effective business processes are crucial to enterprise success. Common types of business processes that help companies drive business goals include the following:
- Developing and making a new product.
- Fulfilling a product order.
- Managing customer service.
- Assimilating a new employee.
These business operations can entail hundreds or even thousands of tasks and the approvals required to complete them. They typically involve people, IT systems and other machinery within the business and can also involve business process outsourcing providers. A well-designed business process breaks these tasks into structured, repeatable steps that workers can follow to produce consistent results. The repeatable steps help organizations predict the resources they need, lowering the risk of under- or over-allocating resources. Measuring the steps reveals weak links and bottlenecks, pointing the way to potential business process improvements.
BPM expert Michael Rosemann, professor of innovation systems at Queensland University of Technology in Australia and director of the university's Centre for Future Enterprise, likened business processes to the lifeblood of an organization.
"Like blood vessels, they fill it with life and determine its way and speed of value creation as well as the cost to serve its customer base," wrote Rosemann in the forward to Business Process Change: A Business Process Management Guide for Managers and Process Professionals by Paul Harmon. "Thus processes reflect not only organizational productivity, effectiveness, and efficiency, but also its reliability, complexity, and ultimately its culture."
A poorly conceived or ill-managed business process can therefore damage a company, impeding productivity and efficiency. And, if an ineffectual process is automated as is, it can actually amplify poor performance, undermining business goals.
BPM's systematic methods for discovering, modeling, improving, automating and continuously monitoring business processes are designed to ensure that doesn't happen. Done well, BPM helps companies deliver products and services efficiently at lower cost and aligns processes to business goals. A BPM approach to process improvement and automation also helps companies adapt to changing needs -- another reason for its relevance today, according to process experts.
The intense pace of business change in the 21st century shows no signs of slowing. Organizations must be able to respond quickly and effectively to succeed. "Playing catch-up is no longer a viable strategy -- things are changing too fast," explained BPM expert Daniel Morris, an independent consultant who specializes in business transformation. Moreover, successful companies are leapfrogging the competition with new methods, ideas and products.
BPM proponents like Morris make the case that the ability to facilitate cost-effective, low-risk and rapid business process change is BPM's underlying value proposition. "It enables you to continuously reinvent your business operations, injecting innovation as you go and do so over the long haul," he said.
Let's find out how.
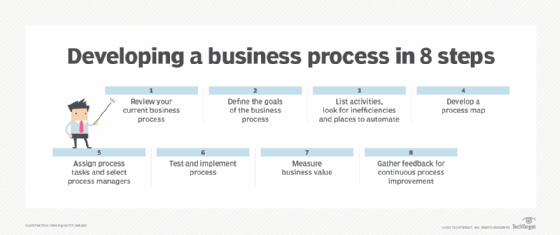
What are the stages of the BPM lifecycle?
BPM, as noted, covers a lot of ground. Many BPM experts refer to the following five phases when describing a BPM project:
- Design. Analyze the existing process to see what can be improved. Then, develop the business process as it should ideally exist using standardization and automation.
- Model. Look at how the redesigned business process operates in different scenarios.
- Implement. Execute improvements, including standardization and process automation.
- Monitor. Track improvements to see how they perform.
- Optimize. Continue to improve the business process on an ongoing basis.
Some practitioners include a sixth step -- business process reengineering (BPR) – to refer to what happens when adjustments to an existing process no longer drive the desired business results and require radical reinvention, usually involving the heavy use of automation. Other BPM lifecycle schemas include separate phases for analyzing, automating and managing business processes.
While the BPM lifecycle seems straightforward enough, each phase requires careful planning. Business processes typically span multiple systems and departments. Onboarding an employee, for example, could involve not only HR, but also the IT department to issue security credentials and computer equipment, Finance to set up tax documents, training programs for on-the-job education and so on.
Improving a business process also typically involves many groups of people, including the following:
- Executives in charge of aligning business processes with business goals.
- BPM specialists to help develop processes.
- Owners of the business process.
- Employees carrying out the work.
- IT professionals responsible for implementing the BPM-enabling tools.
Moreover, the work of discovering and analyzing existing workflows, generating and testing new models and optimizing a business process can generate thousands of documents. There is a lot of room for failure if BPM is not managed well.
BPM best practices
As BPM has matured, best practices have emerged to help keep this complex process improvement work on track. The to-do list begins with understanding that BPM is a business project, not a technology project, according to Morris.
"While technology updates and application development and enhancement are normally part of mid-to-large BPM initiatives, the primary focus … should be on business operations and organizational management," he said. A management and operations focus "ensures that direct, measurable business improvement can be continually delivered in a controlled manner as the business evolves."
Establishing a BPM Center of Excellence is a best practice that midsize and large companies might want to consider. Other tips from Morris, among 16 he listed overall, include the following:
- Create interdisciplinary teams.
- Use a formal BPM methodology.
- Use simulation modeling.
- Add performance measurement with clearly defined KPIs into the workflow models.

What are the benefits of business process management?
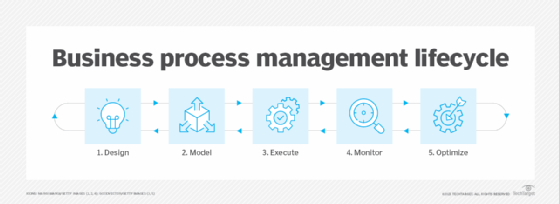
BPM's structured approach to managing business processes improves the quality of work and operational efficiency -- the two primary reasons companies adopt it. A well-executed BPM program can eliminate waste, cut errors, save time, reduce costs, improve compliance, increase agility, support digital transformation and ultimately help deliver better products and services to customers.
"BPM allows organizations to streamline workflows by automating tedious tasks, such as data management, data flows, data entry approval processes and report generation," said Isaac Gould, research manager at Nucleus Research.
BPM can also be an effective management tool for the following reasons:
- BPM's focus on standardizing processes reduces the risk of human error.
- Embedded analytics gives managers more visibility into process performance and helps them identify bottlenecks.
- Automation tools increase efficiency and let employees focus on tasks that require human expertise and interventions.
- All of the above give employees more time to identify other process enhancements and automations for continuous improvement of business processes.
Done well, the benefits of BPM permeate practically every aspect of operations, as illustrated in the chart below.
What are the challenges of business process management?
Challenges abound in any business initiative that involves changing the status quo. That is especially true of BPM, where the complex work of process improvement spans different roles, systems and ways of working.
To maximize the benefits of BPM, organizations must be prepared for the challenges they might encounter and have a plan for addressing them.
The following obstacles are the most common reasons for BPM failures, according to BPM specialists:
- Lack of executive buy-in and support.
- Unclear business goals and objectives.
- Inadequate testing infrastructures.
- Confusion about the right tool for the job.
- Hidden processes vulnerable to breakdowns.
- Poor process visibility and traceability.
- Inflexible third-party contracts and incentives.
Business process management certifications
IT certifications boost your professional credibility and marketability. Programs that require recertification also help you stay current. Check out "Top 10 business process management certifications for 2024" for a guide to BPM certification programs and how they can help your career.
Different categories of business process management
Because BPM is so broad and typically involves the use of various tools, some BPM experts talk about the discipline in terms of the following categories:
- System-centric. This type of BPM focuses on processes involving workflows in business systems that operate without much human intervention and are integrated into enterprise applications. Automated processes in customer relationship management and enterprise resource planning systems are two examples.
- Human-centric. BPM can also focus on process flows that people handle. These processes include ones in business applications that have features designed for human interaction, such as a well-designed user interface, alerts and notifications.
- Document-centric. This approach centers on documents, such as the process of formatting, signing and verifying contracts. Often, business process management tools specialize in a specific document-centric task, such as signing documents.
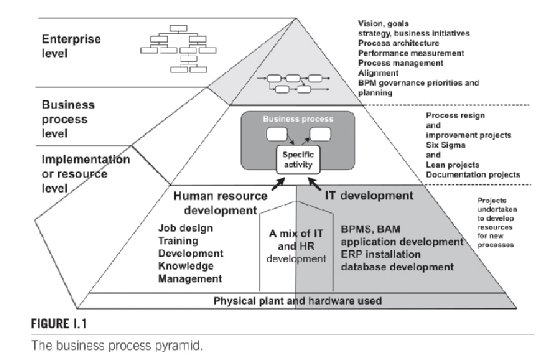
'Levels of concern' in BPM
In Business Process Change, Harmon argued that it's useful to distinguish between the various "levels of concern" in BPM initiatives, which he identified as the enterprise level, business process level and implementation or resource level. "Projects or activities at different levels require different participants, different methodologies, and different types of support," he wrote.
Harmon offered the example of a BPM project focused on a company's supply chain management process. The project might be triggered by an enterprise-level BPM group that decides the company's supply chain is not operating efficiently, initiating a redesign of the process. The redesign team undertakes a study and recommends certain changes, which must be approved by senior management. In this example, the redesign involves the acquisition of a new ERP system, which brings in the IT department. It also creates new job roles that require training courses, bringing in HR.
Harmon's three levels of concern in BPM are shown below in Figure I.1 from his book.
BPM examples and applications
BPM applications are used in many departments within an organization to improve and streamline processes. Examples of how it is used to achieve business objectives include the following:
- Human resources. BPM software can make HR departments more efficient by, for example, simplifying the review of timesheets. Onboarding new hires is another HR area where BPM can improve and speed up the many steps of the process. When document-centric HR tasks are automated, it cuts the use of paper forms throughout a company.
- Finance. Finance departments receive a variety of documentation from both system-centric and human-centric processes. They receive a large volume of emails and paper forms about the company's internal and external financial processes. For example, a BPM platform enables finance departments to process employee travel requests faster. It can also streamline purchasing processes.
- Sales. Sales teams also deal with a mix of human- and system-centric processes. BPM tools can coordinate the exchange of sales quotes and invoices, and ultimately shorten sales cycle processes and workflows.
Different types of BPM technologies
Business process management software (BPMS) is designed to automate the improvement of business processes. Sometimes referred to as BPM systems or suites, BPMS is a collection of different types of technologies that include the following:
- Process mining tools for the discovery, representation and analysis of the tasks that drive business processes.
- BPMN tools for diagramming business processes.
- Workflow engines to automate the flow of tasks that complete a business process and support workflow management.
- Business rules engines (BREs) to enable end users to change business rules without having to ask a programmer for help.
Our definition of business process management software explains in detail what this software is, why it's used and the standard features you can expect. Here is an overview of some of the new developments in BPMS:
iBPMS. The term intelligent BPMS (iBPMS) was introduced by research firm Gartner, Inc. It is now widely used by BPM vendors to underscore how the use of advanced technologies -- such as real-time analytics, machine learning, complex event processing, business activity monitoring and other systems -- have made process automation more data-driven and dynamic. These iBPMS products also come with advanced social and collaboration capabilities.
LCNC. BPM's increasing use of low-code/no-code (LCNC) technology means that businesses no longer need to depend solely on professional coders to optimize their business processes. Business analysts and even business users can work together with developers to model new business processes.
RPA vs. BPM. Robotic process automation (RPA) and BPM, considered by some to be competitors or at best frenemies, today function as complementary partners.
RPA programmable software tools, or bots, automate manual, repetitive, rules-based tasks by mimicking the way humans click and type in the business applications they use to do their jobs. This relatively user-friendly software can also automate access to legacy software applications that lack modern application programming interfaces, or APIs -- another selling point. RPA is best suited for automating discrete tasks rather than complex business processes, but this limitation is diminishing as the software evolves.
BPM, as explained in this guide, is a discipline, not a technology. It aims to improve processes using a set of principles and techniques derived from methodologies such as Six Sigma, total quality management and lean management. BPM may or may not involve automation and, as proponents stress, it is as much a mindset as it is a technical discipline: Companies that adopt BPM must see the value of taking a process approach to fulfilling business goals and the value of continuous process improvement. As noted, BPM's collection of enabling technologies -- BPMS -- has evolved to better address the business need for continuous improvement and agile transformation at scale.
Bottom line: RPA products are becoming better at scaling process automation, and BPM software platforms increasingly offer RPA as part of their toolkit.

Business process management tools and vendors
There is an ever-expanding number of BPM tools on the market. In recent years, traditional BPM vendors have evolved their platforms to take advantage of modern architectures, LCNC development, RPA, process mining, holography and a host of AI capabilities, including voice recognition, natural language processing, AI-enhanced virtual reality and generative AI.
Below is a list of top BPM vendors, in alphabetical order. They were selected by BPM consultant Morris based on his extensive work experience and research that included discussions with colleagues and an analysis of industry articles and vendor literature. The list is as follows:
- Appian.
- Agile Point.
- Bizagi.
- iGrafx.
- Kissflow.
- Microsoft.
- Newgen.
- Nintex K2.
- Oracle.
- Pegasystems.
- Progress Software.
- Trisotech.
You can read his detailed take on the products from the vendors in "12 top business process management tools for 2024."
Cost of BPM. According to experts like Morris, the cost of a BPM initiative varies widely, depending on the scope of the project, the number of users, the volume of transactions per hour and the number of locations that will access the applications and annual usage, among other factors. Once project leaders figure out how the company wants to use BPMS currently and down the line, they then must dig into which BPMS capabilities are required and which would be nice to have but aren't mandatory.
In addition to the vendor pricing, there are computing costs associated with data storage, cloud usage and tech training fees. Pricing for a BPM suite could range from $50,000 per year for improving a single process to $1 million per year at a large corporation using BPMS for multiple processes or in multiple products. Another important factor when buying BPMS? Everything is negotiable, Morris stressed.

What is the future of business process management?
BPM -- a structured approach to the improvement of business processes -- is not a new discipline, but it is an evolving one, driven forward by the dynamic nature of how work and business in the 21st century gets done. The need to operate in a digital marketplace, the increased shift to remote work triggered by the COVID-19 pandemic and, more recently, the integration of AI capabilities into business software and innovation in automation tools have pushed companies of all sizes to reassess the processes they use to fulfill their business goals.
BPM, and the technologies that support it, have evolved to meet these new needs. The following is a brief rundown of recent and emerging trends in BPM:
- Citizen developer tools are driving the democratization of BPM, enabling more users across the enterprise to identify, implement and measure new ways to improve processes.
- Intelligent business process automation is improving process efficiency by incorporating AI, machine learning and RPA in workflows.
- The inclusion of BPM functionality into business applications by major software vendors is extending the reach of BPM principles and technology.
- Automated process mining tools have made it much easier for organizations to construct an accurate picture of the activities that make up a process and how they can be optimized. As more process steps move online, the manual work previously done by humans -- and captured in BPM through interviews and observation -- will also be able to be mapped and optimized more easily.
- Adaptive process management, or the ability to do iterative process modeling in real time, will vastly improve the flexibility of process automation.
- Innovations in process modeling are enabling companies to better understand existing processes and ask what-if questions to make improvements.
- Process simulation provides companies with the ability to try out and test changes to business processes prior to production.
- Companies are looking to strike a balance between LCNC development and custom development in the quest for process improvement.
- Generative AI will help companies reimagine business processes and workflows and integrate generative AI into specific tasks.
- A convergence of BPM tools, AI improvements and the implementation of BPM capabilities early in the design and development of core applications is making continuous business transformation more attainable for organizations.
Freelance technology writer Mary K. Pratt and Ben Lutkevich, a TechTarget technical writer, contributed to this article.





